El salto evolutivo más importante en la generación de imágenes con inteligencia artificial es la creación de modelos personalizados. Con eso me refiero a paquetes secundarios que reproducen estilos u objetos específicos, pero también pueden ser utilizados para inyectar el rostro de una persona en escenarios únicos. Esto es posible gracias a la plataforma Dreambooth, desarrollada por Google Research y la Universidad de Boston. La aplicación más popular de DreamBooth en estos días es el fine-tuning de modelos compatibles con Stable Diffusion, y hoy te explicamos cómo hacerlo.
Tabla de contenidos
Superando límites
De los tres modelos disponibles para la generación de imágenes con inteligencia artificial, Stable Diffusion ha demostrado ser el más flexible. ¿Por qué? Dos razones: Por un lado, es gratuito y open source, y por el otro, se lleva muy bien con modelos alternativos. ¿Pero de dónde vienen esos modelos? De los mismos usuarios, que aprovechan su hardware de alta gama o las opciones gratuitas en línea para entrenarlos.
El problema del entrenamiento personalizado o «fine-tuning» de Stable Diffusion es su consumo de VRAM. Entrenar un modelo con poca memoria de vídeo es casi imposible, sin embargo, gracias a la magia de Google Colab, Google Drive, HuggingFace y el canal DotCSV en YouTube, hoy podemos hacerlo sin demasiados sobresaltos, y sin invertir miles de euros en hardware. Los requerimientos técnicos serán explicados en cada paso, por lo tanto, ¡no saltees nada!
Entrena tu propio modelo de generación de imágenes con Dreambooth
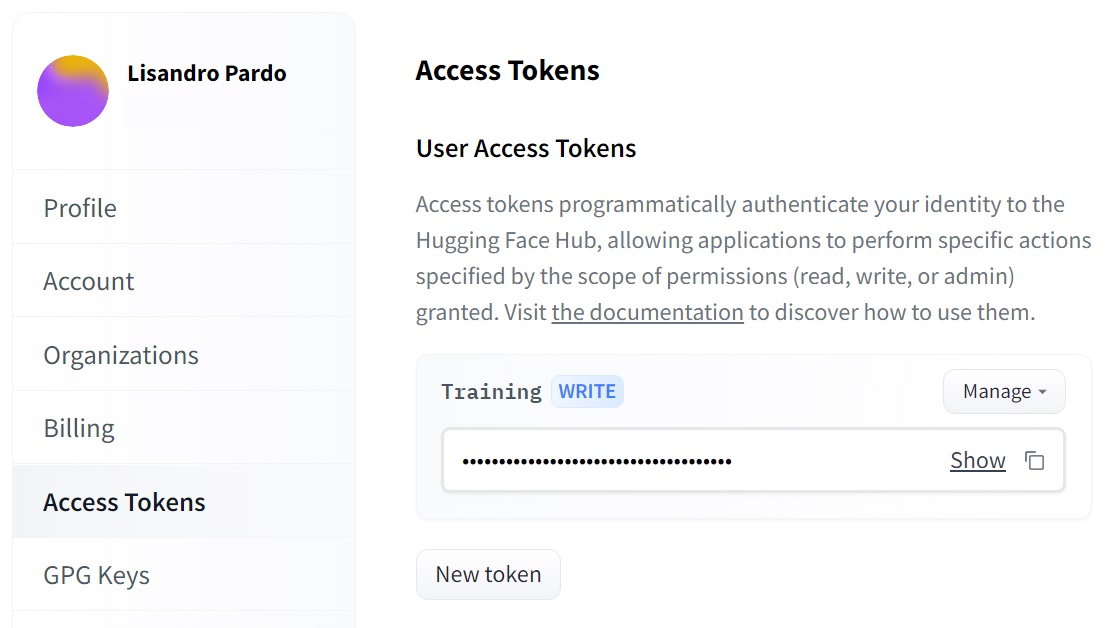
- El primer paso es dirigirte a la página de HuggingFace y crear una cuenta. Todo lo que pide es un correo electrónico y un nombre de usuario. Esto es importante porque necesitamos uno de los tokens de acceso a la plataforma. Una vez creada la cuenta, ve a Settings -> Access Tokens, y haz clic en New token. Asigna un nombre, y especifica la función Write. No te vayas muy lejos, porque deberás copiar el token de aquí más tarde.
- Luego deberás definir qué clase de modelo deseas entrenar a través de una selección de imágenes. El promedio recomendado es de 20… y deben ser variadas. El objetivo es demostrar un estilo, un concepto, un formato, una idea. Por ejemplo, supongamos que quieres un modelo inspirado en fotos Polaroid. Si sólo te enfocas en Polaroids de retratos, el modelo nunca saldrá de ese molde, cuando lo ideal es reproducir los detalles, los errores, el «calor» y la esencia «vintage» de esas fotos.
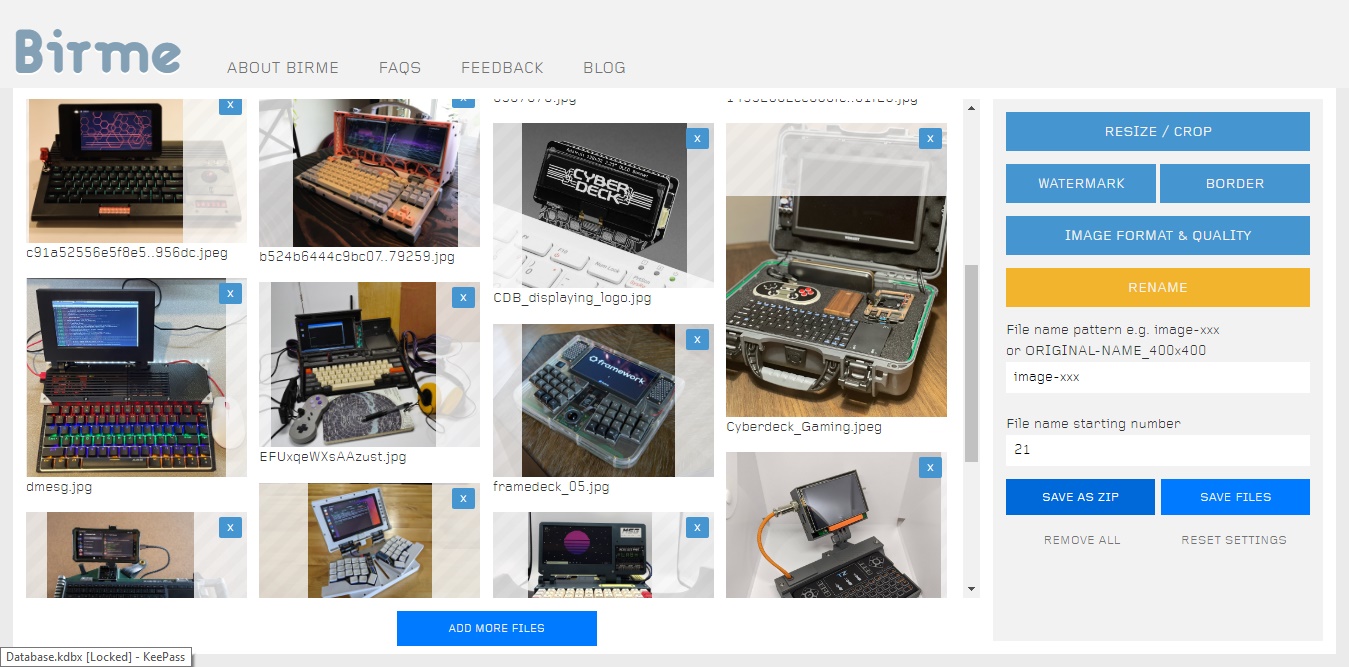
- El tercer paso es sencillo: Ajustar las imágenes a un tamaño exacto de 512 x 512 píxeles. El portal Birme del cual hablamos recientemente te permitirá hacer esto en tiempo récord, ajustando el tamaño y recortando cualquier excedente. Guarda las imágenes en una carpeta temporal, ya volveremos a ellas.
- Ahora es cuando ingresamos al entorno de Google Colab configurado por DotCSV. ¿Mi primera recomendación? No tengas miedo. Al principio parece algo diseñado por extraterrestres, pero en realidad se trata de una interfaz «paso a paso» más espartana de lo normal. Antes que nada, ve a «Entorno de ejecución», ingresa en la sección «Cambiar tipo de entorno de ejecución», y asegúrate de que «GPU» sea la opción seleccionada. Esto confirmará que Google Colab debe asignar una tarjeta gráfica adecuada para la tarea.
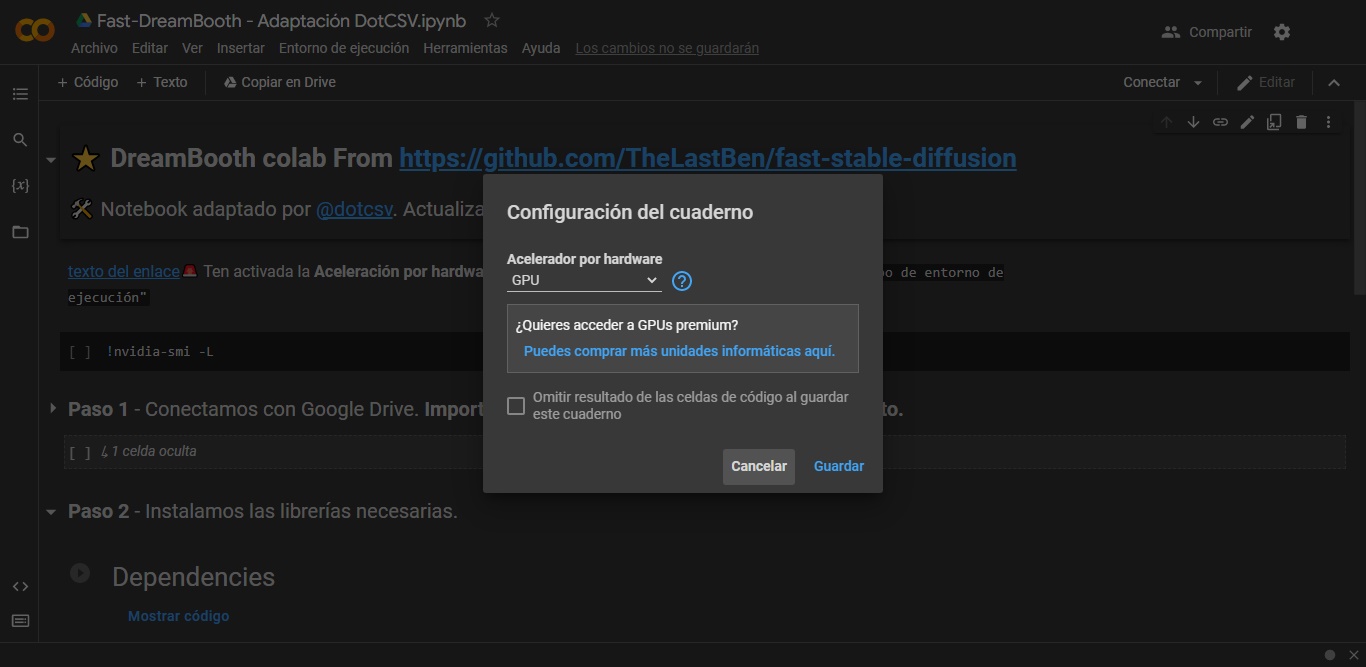
- El entorno de Google Colab nos invita a seguir sus pasos. Presionamos el botón Play en el paso 1, y aceptamos la advertencia para asociar nuestro Google Drive con el entorno. Google Drive debe tener un mínimo de 4 GB líbres para esto, y mi sugerencia es usar una cuenta alternativa.
- Después presionamos el botón Play que se encuentra junto a Dependencies. Tal y como lo indica su nombre, esto instalará todas las dependencias necesarias para la correcta ejecución de Dreambooth. Afortunadamente, no tarda demasiado.
- El paso 3 activa el campo donde debemos ingresar el token que generamos en HuggingFace. Un clic en la flecha abrirá el menú, copiamos el token y lo pegamos en «HuggingFace_Token». Ignora el resto de las opciones, y presiona Play. Espera hasta que termine.
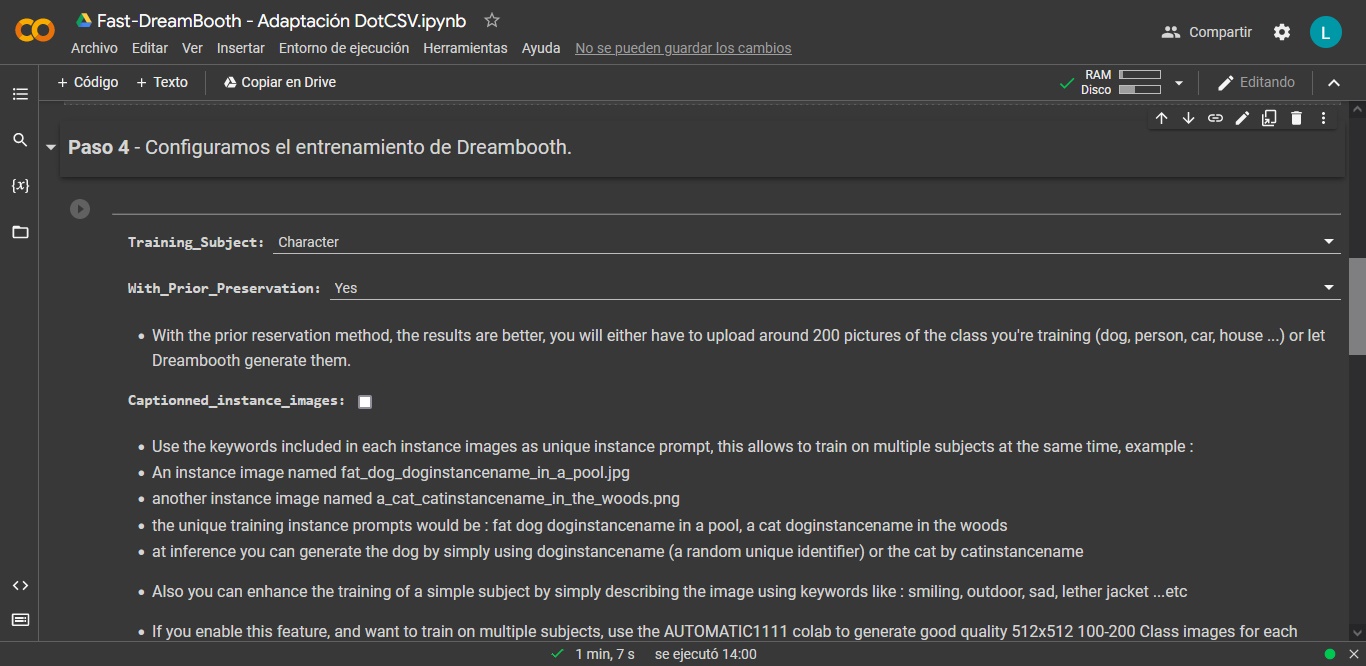
- El cuarto paso solicita datos sobre el entrenamiento de Dreambooth, y esto cambia dependiendo de tus deseos: ¿El plan es entrenar a una persona, o un objeto? ¿Tal vez un artista o una serie de TV? Elige la opción adecuada de la lista en el campo «Training_Subject», y luego modifica la expresión en «Subject_Type» siguiendo los ejemplos que aparecen abajo. Sin embargo, toda tu atención debe ir a «Instance_name». Esto es el comodín, la palabra clave que usarás en los prompts para «activar» el contenido que has entrenado. Se recomienda una palabra rara, que no sea confundida con otra cosa por Stable Diffusion.
- Al presionar Play en el paso 4, Google Colab habilitará un botón de carga para subir las imágenes que servirán como referencia en el entrenamiento. ¡Recuerda, deben ser de 512 x 512!
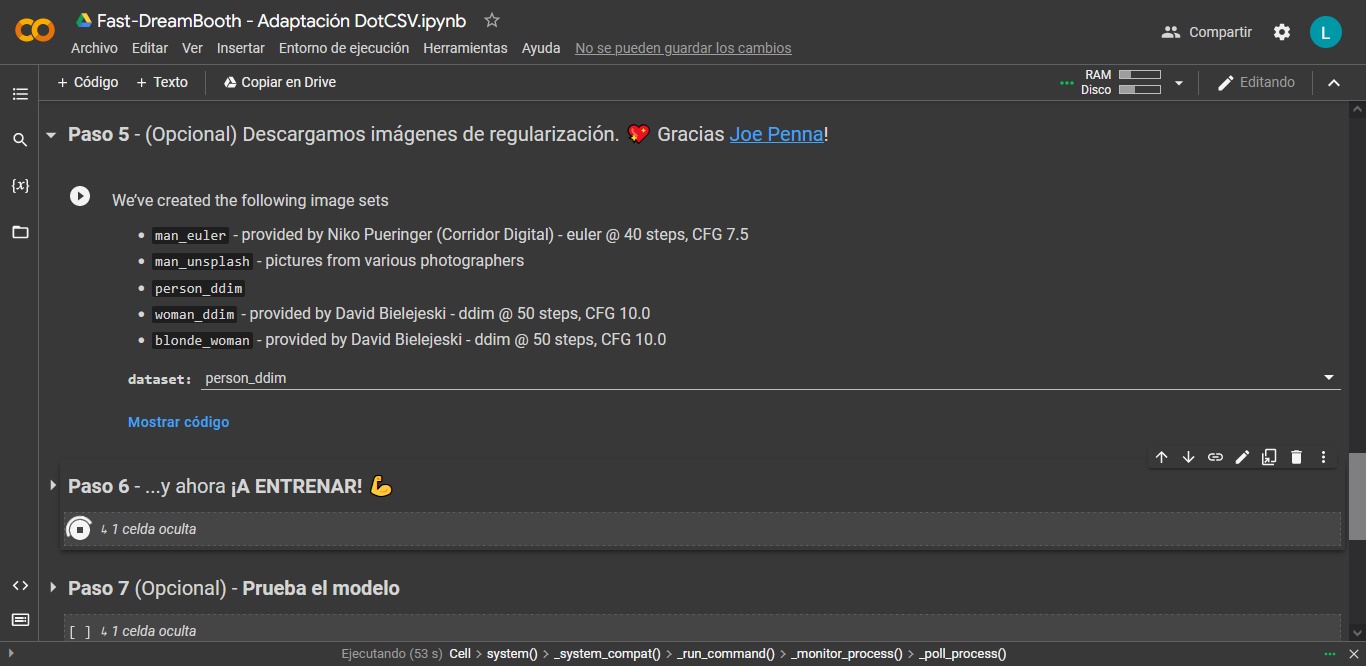
- El quinto paso es opcional, y especialmente útil cuando creamos modelos de personas. En nuestra prueba no es necesario, pero allí encontrarás cinco valores diferentes. «person_ddim» es el modo por default, no dudes en cambiarlo para experimentar.
Y ahora, a esperar

El botón Play del paso 6 inicia el proceso de entrenamiento, y a partir de aquí… paciencia. ¿Cuánto tarda? Para un paquete estándar de 20 imágenes con 1.600 pasos, el promedio es de una hora, muy razonable considerando que estamos accediendo a gigabytes enteros de VRAM sin cargo. El nivel de actividad en Google Colab y la tarjeta gráfica que fue configurada para el proyecto también influyen en su rendimiento final.
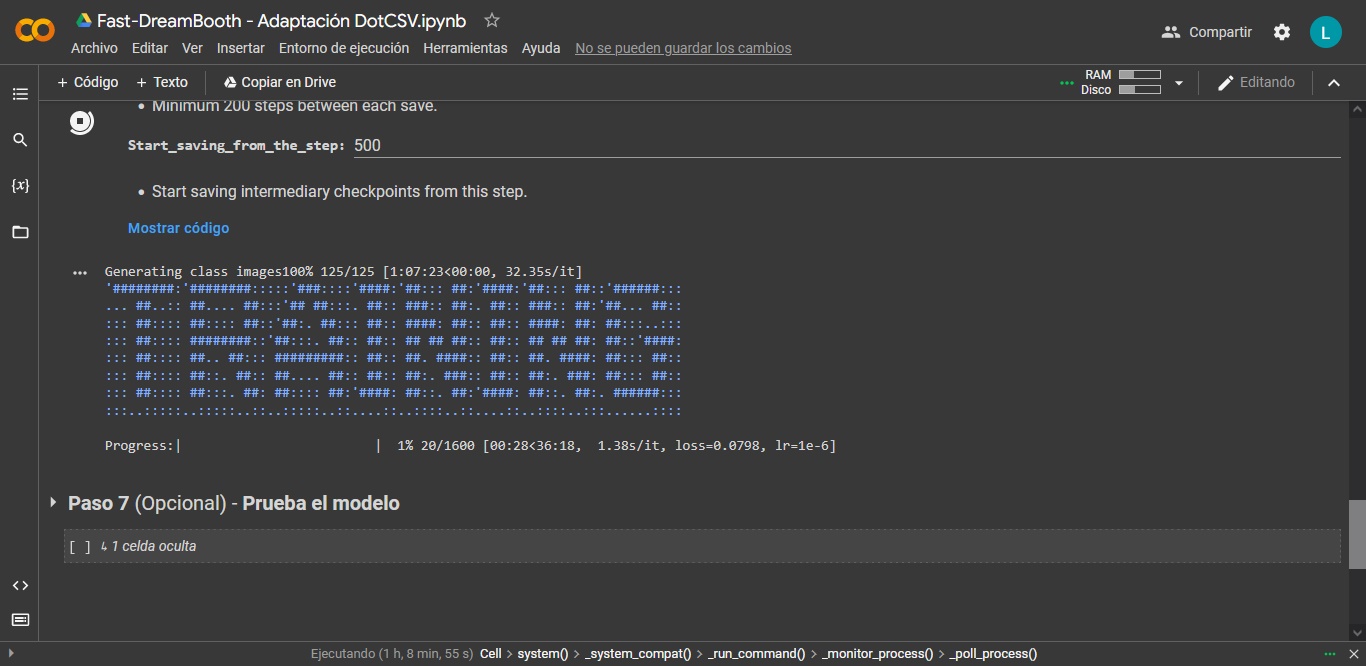
Con el modelo ya entrenado, sólo quedan dos cosas por hacer: Evaluarlo en línea haciendo uso del paso 7, o descargar el archivo ckpt de nuestra cuenta de Google Drive para su ejecución offline con Automatic1111. No olvides agregar tu palabra clave a los prompts, o de lo contrario nunca verás resultados correctos entre las imágenes generadas.
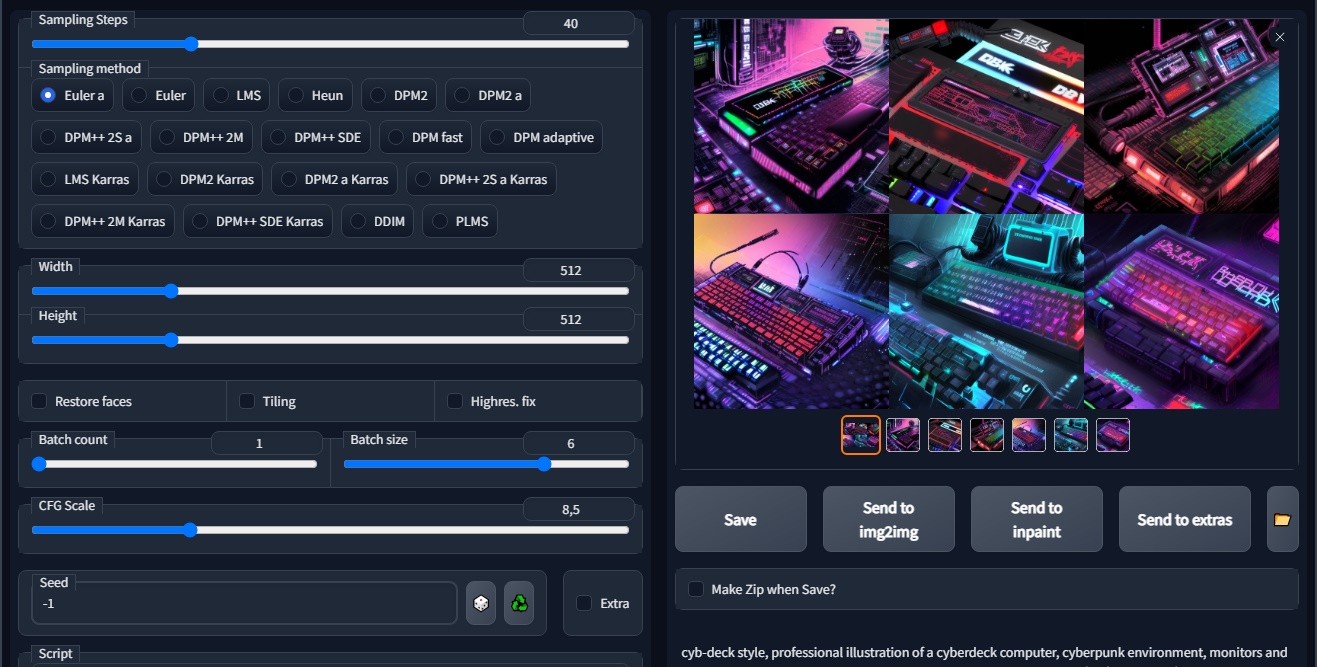
En resumen, Dreambooth es una herramienta extremadamente poderosa, pero requiere algunas horas de vuelo. En ciertas ocasiones, el entrenamiento no es del todo satisfactorio, y es posible que te veas obligado a intentarlo de nuevo con un set diferente de imágenes. ¡No bajes los brazos!
HuggingFace: Haz clic aquí
Dreambooth en Google Colab: Haz clic aquí

Me he quedado trabado en el 2do paso? no encuentro la opción