

Pintan desnudos extraños, colorean dibujos, pulverizan al Buscaminas y hasta se postulan para cargos políticos. ¿Hay algo que las inteligencias artificiales no puedan hacer? Su lista de restricciones se está volviendo cada vez más pequeña, y ahora debemos sumar la reconstrucción de fotografías corruptas e incompletas. El proyecto está a cargo de un grupo de investigadores bajo el ala de Nvidia, que entrenaron a una red neural con tres datasets especiales sobre una plataforma basada en las impresionantes tarjetas Tesla V100.
Uno de los nombres que más ha estimulado el desarrollo de inteligencias artificiales es Nvidia, y la razón de fondo no es otra más que su hardware. La página oficial de la tarjeta Tesla V100 indica que al ser utilizada en grupos de ocho unidades logra entrenar a una red neural en un tercio del tiempo que le tomaría a ocho tarjetas de la generación anterior Tesla P100. Si hacemos un poco de memoria, la demo de raytracing que publicó Epic Games usó cuatro Tesla V100, por lo tanto, imaginen lo que ese poder de fuego puede hacer por una inteligencia artificial. De hecho… no, no lo imaginen. Mejor vean este vídeo:
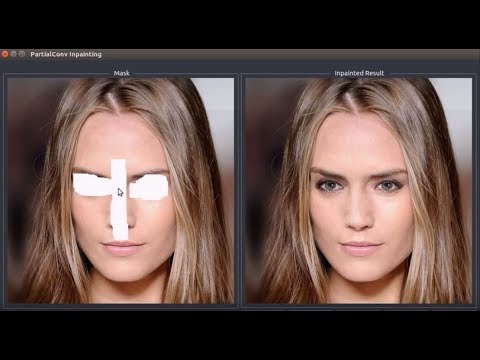
Un equipo de investigadores en Nvidia entrenó a una red neural sobre el marco de trabajo PyTorch utilizando los datasets ImageNet, Places2 y CelebA-HQ, además de una sola tarjeta Tesla V100 de 16 GB, con el objetivo de reconstruir, reparar, sustituir y corregir diferentes aspectos en una imagen. Básicamente, el usuario crea «agujeros» en la fotografía, y la inteligencia artificial se encarga de llenarlos con una alternativa convincente. La demo nos enseña que el sistema posee cierta fortaleza al eliminar líneas y otros objetos artificiales, pero tiene algunas dificultades al procesar rostros humanos. Aún así, los primeros retoques en la cara de Ernest Borgnine son notables.
De acuerdo con los investigadores, es la primera vez que se demuestra la utilidad y la eficacia del aprendizaje profundo en modelos dedicados al procesamiento de «agujeros» con forma irregular (independientemente del tamaño, ubicación, o distancia de los bordes), mientras que otros proyectos previos se han concentrado en regiones rectangulares cercanas al centro de la imagen, que demandan un costoso postprocesamiento.
